Semantic Kernel is an excellent orchestration tool for integrating Generative AI into existing applications, such as a chatbot. It features Connections and plugins/functions, simplifying the process of linking to your OpenAI service or incorporating specific logic that an LLM cannot handle. It also allows for predefined prompts that an application may require. Detailed information on Semantic Kernel is available on the Microsoft Learn pages.
One notable feature yet to be discussed is the use of Plans. Plans consist of predefined steps necessary to answer a specific question. These steps can include executing a plugin, calling a prompt, setting variables, all of which as essential for responding to a user’s particular inquiry. While there is an option for Semantic Kernel to determine which plan to execute, there are some drawbacks to consider.
- Creating a plan also consumes tokens, which could be unnecessary if your chatbot is designed to answer specific questions or topics. This means that there’s a high likelihood the same plan could be reused multiple times, eliminating the need to constantly request the LLM to create a new plan. It’s more efficient to have a set of standard plans that can be applied to recurring inquiries, saving on token usage and streamlining the chatbot’s operation.
- The creation of a plan by an LLM means that outcomes can vary based on slight differences in the questions, leading to some unpredictability. In certain scenarios, it’s preferable to have consistency in the execution of plans, especially when the questions are similar. This ensures a predictable and reliable response from the chatbot.
- Currently, it is unclear when Semantic Kernel decides to utilize a plan or which plugin it will select to answer a question, which adds to the unpredictability of the user’s response. It’s important for the response mechanism to be transparent and predictable to ensure user trust and consistent interaction with the chatbot.
To address these issues, Semantic Kernel allows the export of plans created by an LLM and saves them as text files within your application. This enables you to direct the response to a question into a specific plan based on the question’s intent. This means that you cannot simply direct every question to an LLM and expect an accurate answer; instead, you need to create flows that cover the main topics your chatbot is designed to handle. These flows can be captured as plans that execute different steps, such as calling plugins or functions, before generating a response to the user. This approach ensures a more controlled and intentional response strategy, enhancing the chatbot’s effectiveness.
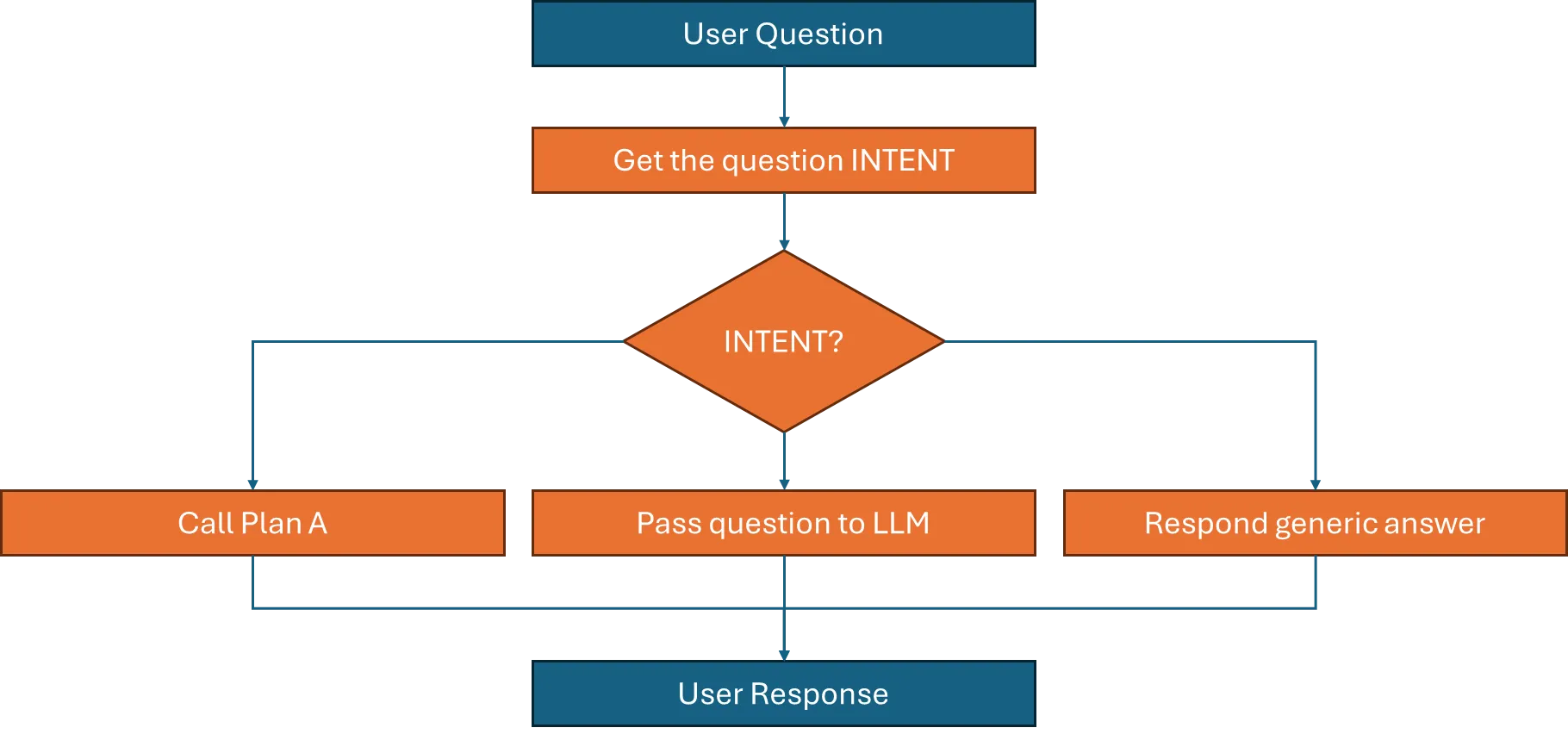
You will also have some default flows where the question is passed to the LLM to generate an answer, or if you prefer not to have your chatbot respond, it can return a generic answer. This ensures that there is a baseline response mechanism in place, either for creating tailored responses or for providing standard replies when necessary.
So in practical terms, how did I implement this into a chatbot?
- In the test application, all plugins and functions have been loaded into Semantic Kernel, which the chatbot will also have access to. You can then pose questions to Semantic Kernel and request it to create a plan detailing how it will respond to those questions.
- After reviewing some results and creating a plan that seems effective, I saved it into a text file. Now, I will test the plan by executing it with all the required parameters. In my example, I need two parameters: the room and the desired status of the lamp.
- Once the plan operates as expected, the next step is to develop a prompt that will extract the user’s intent from their question and determine the appropriate flow to follow. The output of the intent analysis can then be used as an input parameter for the plan, which will in turn respond to the user’s question. If the question does not align with a specific intent, it will trigger a different flow, ensuring that the user still receives a response.
In conclusion, plans are an effective way to define the flows that will respond to the most common questions received by our chatbot. It is beneficial to save these plans to avoid unpredictability and the unnecessary expenditure of tokens to create responses each time a user asks a question. By utilizing user intent prompts, you can determine which flow to follow, and the intent will also provide the necessary parameters to execute the plan.
Once you have this framework established within your application, you can integrate any flow swiftly and expand your chatbot’s capabilities to provide accurate answers to more common questions.
Thanks for reading!
Talk to the author
Contact Steven
IoT Data & AI Domain Lead - Data & AI Solution Architect